
使用 AWS Athena 分析查詢 S3 與 ALB 日誌
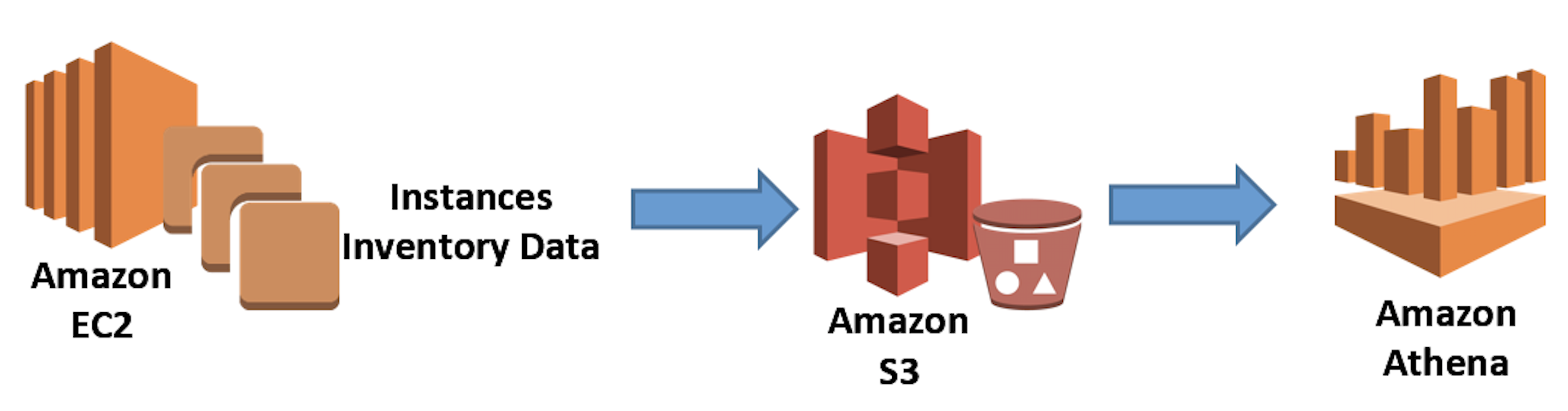
在做大數據分析往往會遇到許多效能性的問題,造成開發者會另外在評估快取機制或是程式端優化的步驟,當引入 AWS Athena 這項服務時讓開發者大大簡化所有複雜的需求,AWS Athena 也是無服務器可以自動擴展,即使在處理更複雜查詢和大型數據集時,也可以依靠它並行執行查詢并快速生成結果。
關於 AWS Athena
將數據作為資源存放在 Amazon S3 中,在 AWS Athena 的部分只需指向 Amazon S3 中存放的位置並定義結構描述,開發者使用標準 SQL 就能解析查詢大規模的資料集。
數據格式
查詢服務使用幾種不同的數據格式,其中包括 ORC、JSON、CSV 和 Parquet,Amazon 建議使用Apache Parquet 將數據轉換為列式存儲格式,因為交互式查詢服務的核心功能遵循計算和存儲的分離,使用壓縮和列格式可以降低查詢和存儲成本,同時進一步提高性能。
Amazon 還建議對數據進行分區,以減少查詢需要掃描的數據量,從而提高查詢性能。
這可以提高性能並降低查詢成本,還可以配對 Amazon EMR 或 Glue 來轉換數據格式,以提高文件結構和格式的效率。
實作資料分析處理
接下來使用 Application Load Balancer 和 AWS S3 的訪問日誌來了解如何使用 AWS Athena 分析存在於 Amazon S3 文件夾中的整個數據檔案。
首先開啟 Athena 服務,在查詢編輯器中執行以下命令來建立一個數據庫:
CREATE DATABASE logs_db設定與查詢 AWS ALB 服務訪問日誌
要了解如何啟用 Application Load Balancer 訪問日誌,您可以閱讀 這篇文章。
在該數據庫中創建資料表結構:
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
new_field string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\"($| \"[^ ]*\")(.*)'LOCATION 's3://your-alb-logs-directory/AWSLogs/<ACCOUNT-ID>/elasticloadbalancing/<REGION>/';上述的語法中需要將 LOCATION 中的值調整為要查詢的 AWS ALB 日誌位置。
示例使用的情境
查詢 ALB 的所有客戶端 IP 地址,並列出訪問次數:
SELECT distinct client_ip, count() as count
FROM "logs_db"."alb_logs"
GROUP BY client_ip ORDER BY count() DESC;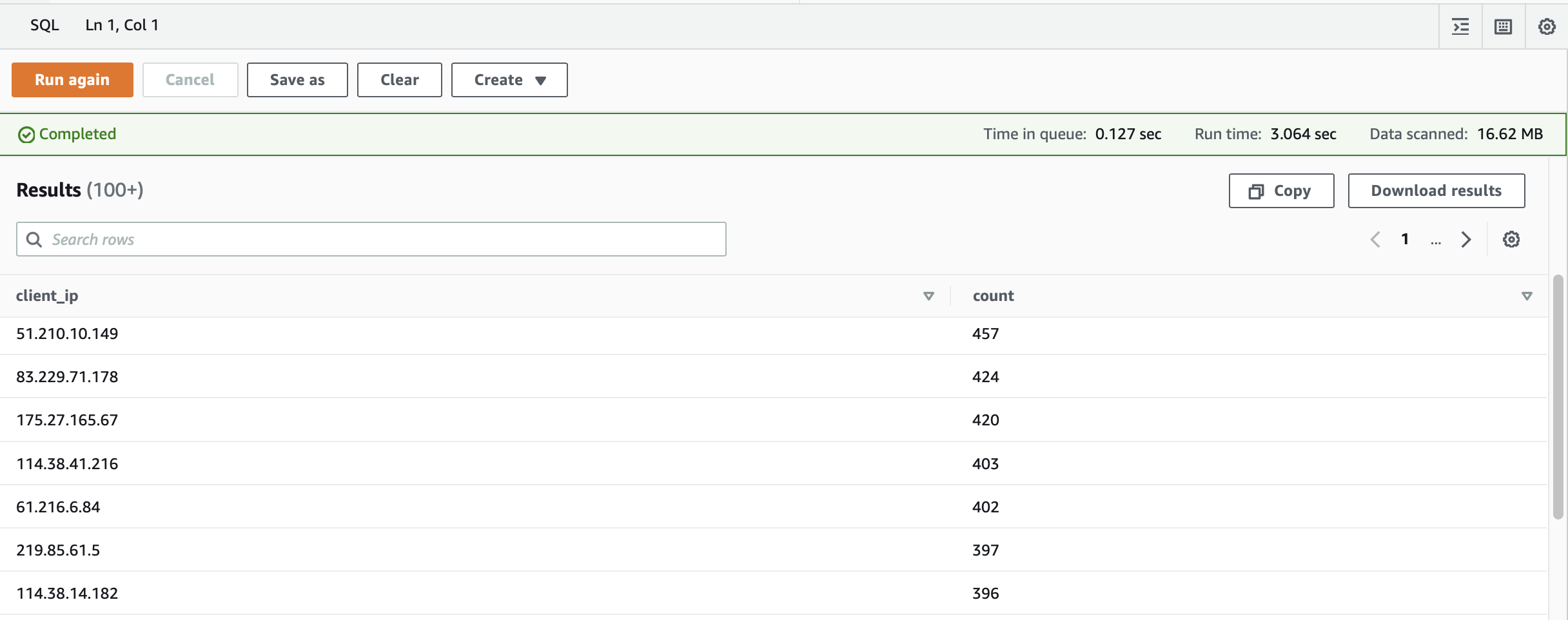
查詢 ALB 有關 HTTP 503 錯誤進行故障排除:
SELECT * FROM "logs_db"."alb_logs"
WHERE elb_status_code = '503' LIMIT 10;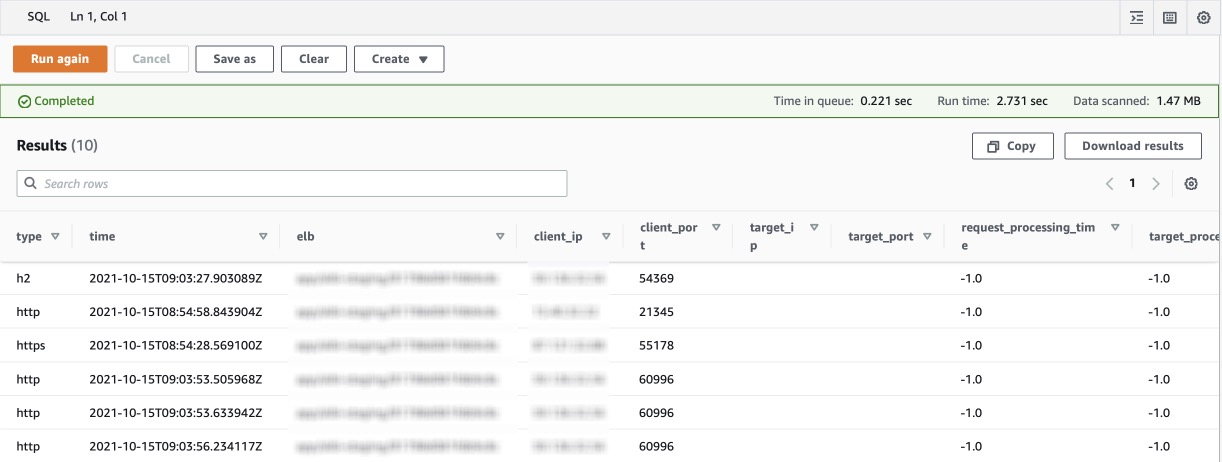
設定與查詢 AWS S3 訪問日誌
要了解如何啟用 S3 訪問日誌,您可以閱讀 這篇文章。
在該數據庫中創建資料表結構:
CREATE EXTERNAL TABLE IF NOT EXISTS s3_logs(
`bucketowner` STRING,
`bucket_name` STRING,
`requestdatetime` STRING,
`remoteip` STRING,
`requester` STRING,
`requestid` STRING,
`operation` STRING,
`key` STRING,
`request_uri` STRING,
`httpstatus` STRING,
`errorcode` STRING,
`bytessent` BIGINT,
`objectsize` BIGINT,
`totaltime` STRING,
`turnaroundtime` STRING,
`referrer` STRING,
`useragent` STRING,
`versionid` STRING,
`hostid` STRING,
`sigv` STRING,
`ciphersuite` STRING,
`authtype` STRING,
`endpoint` STRING,
`tlsversion` STRING)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='([^ ]*) ([^ ]*) \\[(.*?)\\] ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) (-|[0-9]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) ([^ ]*)(?: ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*))?.*$')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://your-s3-logs-directory/prefix/'上述的語法中需要將 LOCATION 中的值調整為要查詢的 AWS S3 日誌位置。
示例使用的情境
查詢在特定時間段內已刪除對象的日誌:
SELECT requestdatetime, remoteip, requester, key
FROM "logs_db"."s3_logs"
WHERE operation like '%DELETE%'
AND parse_datetime(requestdatetime,'dd/MMM/yyyy:HH:mm:ss Z')
BETWEEN
parse_datetime('2021-10-18:07:00:00','yyyy-MM-dd:HH:mm:ss')
AND
parse_datetime('2021-12-06:08:00:00','yyyy-MM-dd:HH:mm:ss');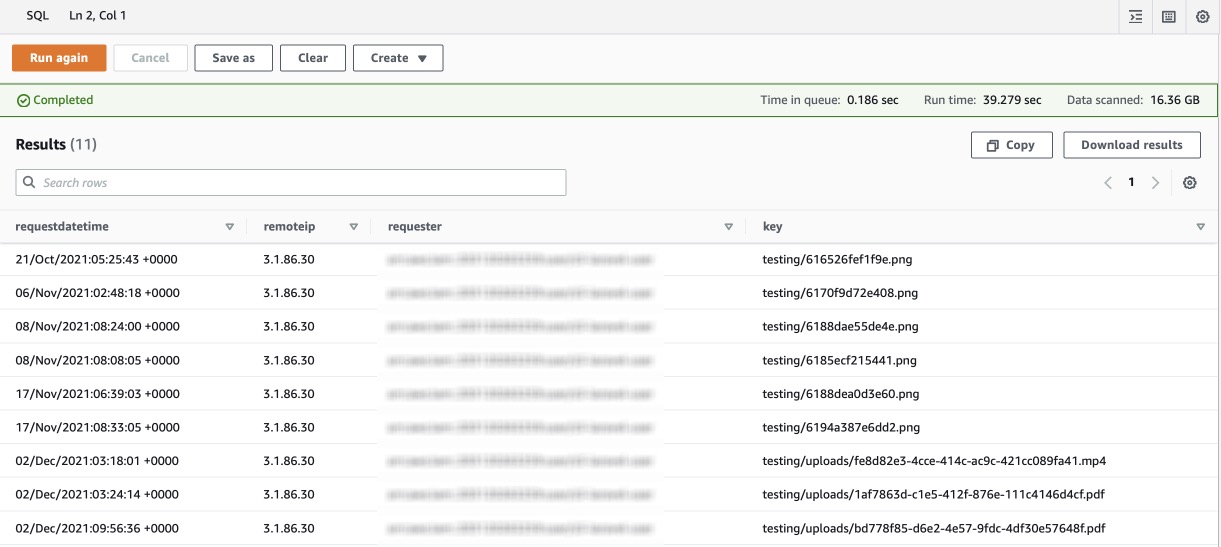
要顯示特定 IP 地址在特定時間段內傳輸的數據量:
SELECT
SUM(bytessent) as uploadtotal,
SUM(objectsize) as downloadtotal,
SUM(bytessent + objectsize) AS total
FROM "apeiro"."s3_access_logs"
WHERE remoteIP = '3.1.86.30'
AND parse_datetime(requestdatetime,'dd/MMM/yyyy:HH:mm:ss Z')
BETWEEN
parse_datetime('2021-10-18:07:00:00','yyyy-MM-dd:HH:mm:ss')
AND
parse_datetime('2021-12-06:08:00:00','yyyy-MM-dd:HH:mm:ss');
優化 AWS Athena 成本
用戶只需為運行的查詢掃描的數據量付費,此外存儲在 S3 中的結果可能會產生存儲費用。
- 每 TB 掃描數據的定價為 5 美元。這意味著您只需為您運行的查詢付費,無需額外費用。
- 查詢四捨五入到最接近的 MB,最小為 10 MB。
- 用戶按常規 S3 費率為存儲的數據付費。
建議用戶使用壓縮數據文件,以列格式保存數據,並定期刪除舊的結果集以保持較低的費用。在 Apache Parquet 中格式化數據可以加快查詢速度並減少查詢費用。
結論
Athena 可協助分析在 Amazon S3 中存放的非結構化、半結構化和結構化資料,當需要管理很多複雜的 AWS 環境時,這種方法就可以簡化很多排查步驟。
或是有相關開發上的功能需求也可以透過程式端連接 AWS Athena 做資料搜集應用,並可以再開發的產品系統上顯示當前伺服器的狀態,對於以往開發要抓取伺服器狀態的工作也簡化了許多。



leave a message
Please note that comments must be reviewed before they are published